Generative image models trained on large scale datasets have achieved unprecedented capabilities, allowing their use in applications both within the vision domain and well beyond. Despite this success, several qualitative and quantitative studies have shown that, at times, models can struggle to generate images with relatively simple concepts, e.g., human hands, objects appearing in groups of four, and negations or object relations.
These failure modes, which we call "conceptual blindspots", can be unintuitive, since one may reasonably expect models have had enough exposure to demonstrations accurately detailing such concepts. This raises the question whether such failures reflect intriguing quirks of certain specific concepts, or whether they are demonstration of a more systematic phenomenon.
To identify and analyze conceptual blindspots in an automated and unsupervised manner, we propose a methodology that elicits concepts in the data distribution that have a mismatch between their odds of generation by the true data-generating process versus the trained model.

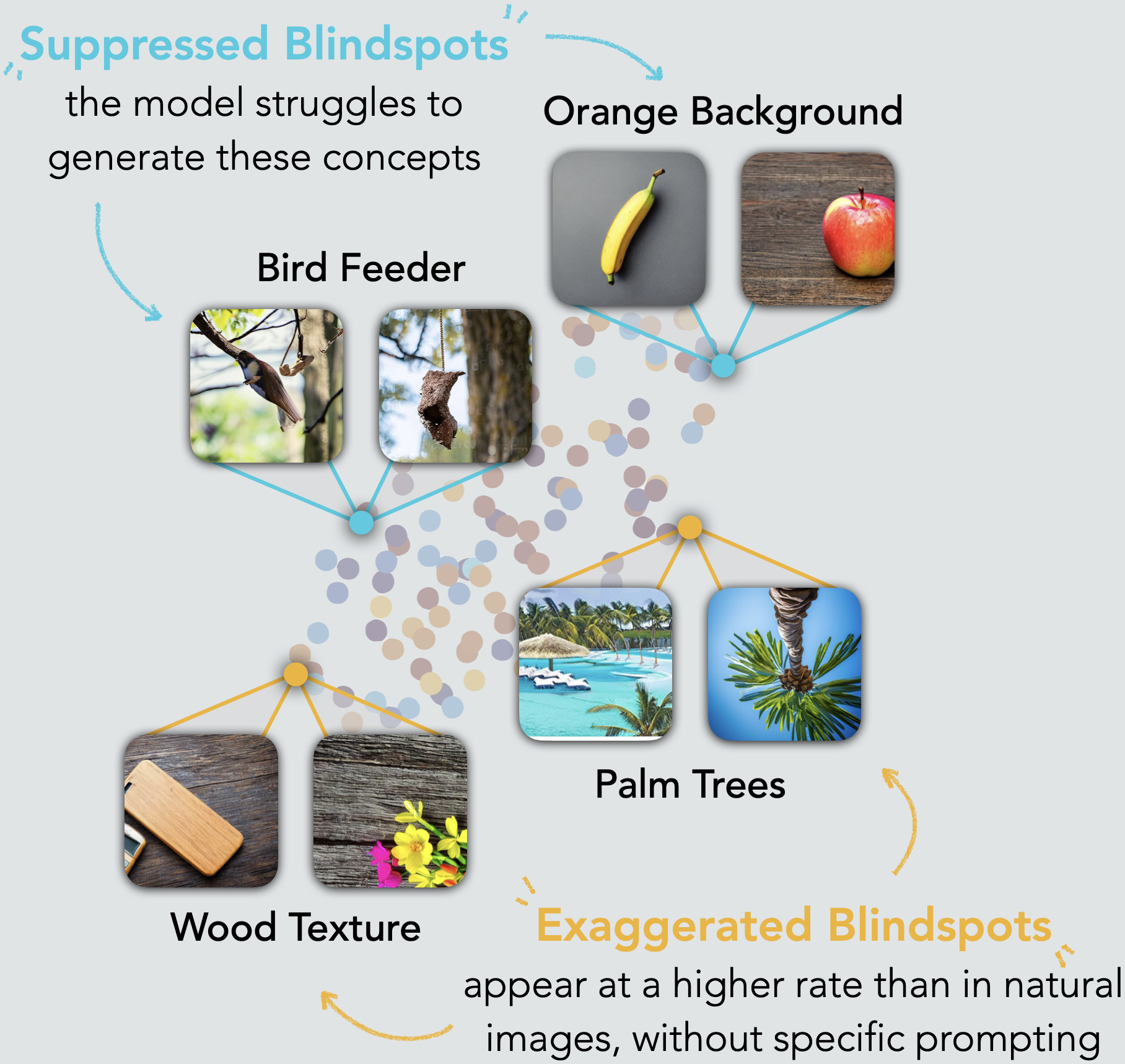
$\delta(k)$ quantifies a model's tendency to over- or under-generate a concept $c_k$ compared to its natural-data frequency. We deem concepts with $\delta(k) < 0.1$ as suppressed conceptual blindspots and concepts with $\delta(k) > 0.9$ as exaggerated conceptual blindspots. The depicted images, generated by four popular generative image models, show examples of conceptual blindspots as well as aligned concepts. The models are completely unable to generate suppressed blindspots (e.g., bird feeder), despite diverse prompting and steering strategies. For concepts with $\delta(k)\approx0.25$ (e.g., traffic sign), the models exhibit substantial deficiencies. In contrast, exaggerated blindspots emerge unprompted, at rates far exceeding their distribution in natural images.
Method
Our method leverages sparse autoencoders (SAEs) to extract and compare concept distributions between natural and generated images. Specifically, we train an archetypal SAE (RA-SAE) on DINOv2 features to decompose images into 32,000 interpretable concept dimensions. For each concept, we compute an energy difference metric δ(k) that quantifies the relative prevalence of concept k in generated images versus natural images.
This metric ranges from 0 to 1, where values below 0.1 indicate suppressed conceptual blindspots (concepts under-represented in generated images) and values above 0.9 indicate exaggerated blindspots (concepts over-represented).
Interactive Exploratory Tool
We release an interactive exploratory tool that enables researchers and practitioners to explore conceptual blindspots across four state-of-the-art generative image models. The tool supports both distribution-level analysis to identify systematic blindspots and datapoint-level examination to reveal specific instances of concept omission or memorization.
To perform the conceptual blindspots analysis on your own model and generate the same visualization, follow our open-source codebase.

The web interface displays a UMAP projection for each evaluated model, where each dot represents a concept, color-coded by its energy difference. When a concept is selected, a detail panel presents illustrative images, statistics, and the most representative natural and generated images $x$ and ${x}^{\prime}$ An ordered list of the concept's co-occurrences is shown alongside global rankings of blindspots.
Results
We analyze four popular T2I models trained—at least in part—on LAION-5B: Stable Diffusion 1.5, Stable Diffusion 2.1, PixArt, and Kandinsky, using 10,000 image-text pairs and their corresponding generations. Our findings include:
Generative image models cannot produce unseen concepts. Even when concepts are present in training data, models show systematic gaps where they either severely under-represent certain concepts (suppressed blindspots) or over-emphasize others (exaggerated blindspots), revealing fundamental limitations in their ability to faithfully capture the full conceptual diversity of their training data.
Post-training reduces conceptual blindspots. Models fine-tuned with DPO show better alignment between generated and natural concept distributions, producing outputs that more closely match real-world frequencies.
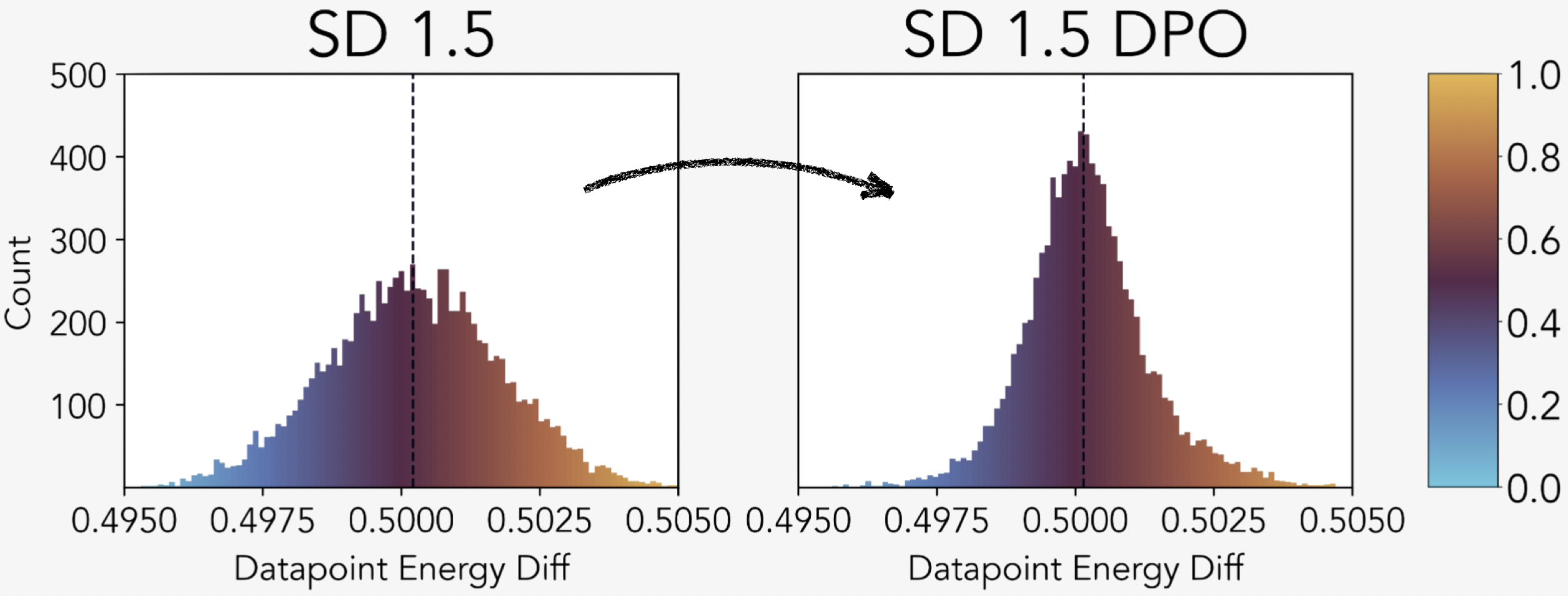
Effect of DPO on Concept Fidelity. Histogram of datapoint-wise energy differences between the synthesized and natural distribution of SD 1.5 models with and without DPO.

Examples with minimal energy differences where models appear to memorize training patterns.
Stress Testing
To stress-test the blindspots identified by our method, we gathered a range of prompts describing these blindspots and used them to generate many images, which were ranked and manually reviewed. While a few hints of the desired concepts appeared, the models generally failed to generate the full concept. This aligns with our method's assessment and supports the validity of the stress test.
Try this four yourself below! Can you get the models to produce these concepts? Share your best results—including the source prompts—on X or Bluesky with #conceptual-blindspots.
Citation
@article{bohacek2025uncovering,
title={Uncovering Conceptual Blindspots in Generative Image Models Using Sparse Autoencoders},
author={Bohacek, Matyas and Fel, Thomas and Agrawala, Maneesh and Lubana, Ekdeep Singh},
journal={arXiv preprint arXiv:2506.19708},
year={2025}
}